IALP 2016 Shared Task:
Dimensional Sentiment Analysis for Chinese Words
Background
Sentiment analysis has emerged as a leading technique to automatically identify affective information within texts. In sentiment analysis, affective states are generally represented using either categorical or dimensional approaches (Calvo and Kim, 2013). The categorical approach represents affective states as several discrete classes (e.g., positive, negative, neutral), while the dimensional approach represents affective states as continuous numerical values on multiple dimensions, such as valence-arousal (VA) space (Russell, 1980), as shown in Fig. 1. The valence represents the degree of pleasant and unpleasant (or positive and negative) feelings, and the arousal represents the degree of excitement and calm. Based on this two-dimensional representation, any affective state can be represented as a point in the VA coordinate plane by determining the degrees of valence and arousal of given words (Wei et al., 2011; Malandrakis et al., 2011; Yu et al., 2015; Wang et al., 2016) or texts (Kim et al., 2010; Paltoglou et al, 2013). Dimensional sentiment analysis has emerged as a compelling topic for research with applications including antisocial behavior detection (Munezero et al., 2011), mood analysis (De Choudhury et al., 2012) and product review ranking (Ren and Nickerson, 2014).
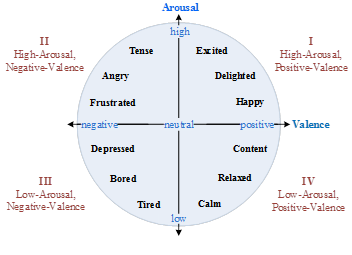
Figure 1. Two-dimensional valence-arousal space.
Task Description
Sentiment lexicons with valence-arousal ratings are useful resources for the development of dimensional sentiment applications. Due to the limited availability of such VA lexicons, especially for Chinese, the objective of the task is to automatically acquire the valence-arousal ratings of Chinese affective words.
Given a word, participants are asked to provide a real-valued score from 1 to 9 for both valence and arousal dimensions, indicating the degree from most negative to most positive for valence, and from most calm to most excited for arousal. The input format is “word_id, word”, and the output format is “word_id, vallence_rating, arousal_rating”. Below are the input/output formats of the example words 勝利(victory), 痛苦 (pain), 乏味 (tedious), and 放鬆 (relaxed).
Example 1:
Input: 0001, 勝利
Output: 0001, 7.8, 7.2
Example 2:
Input: 0002, 痛苦
Output: 0002, 2.4, 6.8
Example 3:
Input: 0003, 乏味
Output: 0003, 3.4, 3.0
Example 4:
Input: 0004, 放鬆
Output: 0004, 6.2, 2.0
Evaluation
The performance is evaluated by examining the difference between machine-predicted ratings and human-annotated ratings (valence and arousal are treated independently). The evaluation metrics include:
- Mean absolute error (MAE)
- Pearson correlation coefficient
A detailed description for the metrics can be found here.
References
- Rafael A. Calvo, and Sunghwan Mac Kim. 2013. Emotions in text: dimensional and categorical models. Computational Intelligence, 29(3):527-543.
- Munmun De Choudhury, Scott Counts, and Michael Gamon. 2012. Not all moods are created equal! Exploring human emotional states in social media. In Proc. of ICWSM-12, pages 66-73.
- Sunghwan Mac Kim, Alessandro Valitutti, and Rafael A. Calvo. 2010. Evaluation of unsupervised emotion models to textual affect recognition. In Proc. of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, pages 62-70.
- Nikos Malandrakis, Alexandros Potamianos, Elias Iosif, and Shrikanth Narayanan, 2011. Kernel models for affective lexicon creation. In Proc. of INTERSPEECH-11, pages 2977-2980.
- Myriam Munezero, Tuomo Kakkonen, and Calkin S. Montero. 2011. Towards automatic detection of antisocial behavior from texts. In Proc. of the Workshop on Sentiment Analysis where AI meets Psychology (SAAIP) at IJCNLP-11, pages 20-27.
- Georgios Paltoglou, Mathias Theunis, Arvid Kappas, and Mike Thelwall. 2013. Predicting emotional responses to long informal text. IEEE Trans. Affective Computing, 4(1):106-115.
- Jie Ren and Jeffrey V. Nickerson. 2014. Online review systems: How emotional language drives sales. In Proc. of AMCIS-14.
- James A. Russell. 1980. A circumplex model of affect. Journal of Personality and Social Psychology, 39(6):1161.
- Wen-Li Wei, Chung-Hsien Wu, and Jen-Chun Lin. 2011. A regression approach to affective rating of Chinese words from ANEW. In Proc. of ACII-11, pages 121-131.
- Liang-Chih Yu, Jin Wang, K. Robert Lai and Xuejie Zhang. 2015. Predicting valence-arousal ratings of words using a weighted graph method. In Proc. of ACL/IJCNLP-15, pages 788-793.
- Liang-Chih Yu, Lung-Hao Lee, Shuai Hao, Jin Wang, Yunchao He, Jun Hu, K. Robert Lai, and Xuejie Zhang. 2016. Building Chinese affective resources in valence-arousal dimensions. In Proceedings of NAACL/HLT-16, pages 540-545.
- Jin Wang, Liang-Chih Yu, K. Robert Lai and Xuejie Zhang. 2016. Community-based weighted graph model for valence-arousal prediction of affective words, IEEE/ACM Trans. Audio, Speech and Language Processing, 24(11):1957-1968.